Pricing Page Teardown: Lovable
Welcome to the first of valueIQ’s pricing page teardowns.


In these teardowns, we use the valueIQ Pricing Intelligence agent to look at the pricing pages of well-known companies to see what we can learn.
We have chosen Lovable as our first example. We do this out of respect. The Pricing Intelligence agent was built in part with Lovable (we also use Vellum as AI middleware), and there are a lot of things to learn about credit-based pricing best practices from Lovable.
You can get the Advanced Report on Lovable’s pricing page by going to the Pricing Intelligence Agent, signing up, and searching for Lovable. The free plan gives you 200 credits per month, so you can download the Advanced Report for Lovable (Advanced Reports cost 120 Credits, Standard Reports cost 30 Credits).
We generate the report by running the Lovable pricing page through the Pricing Intelligence agent. It calls a number of sub-agents that work together to build a deep understanding of Lovable’s pricing, as shown by its pricing page, in a broader context.
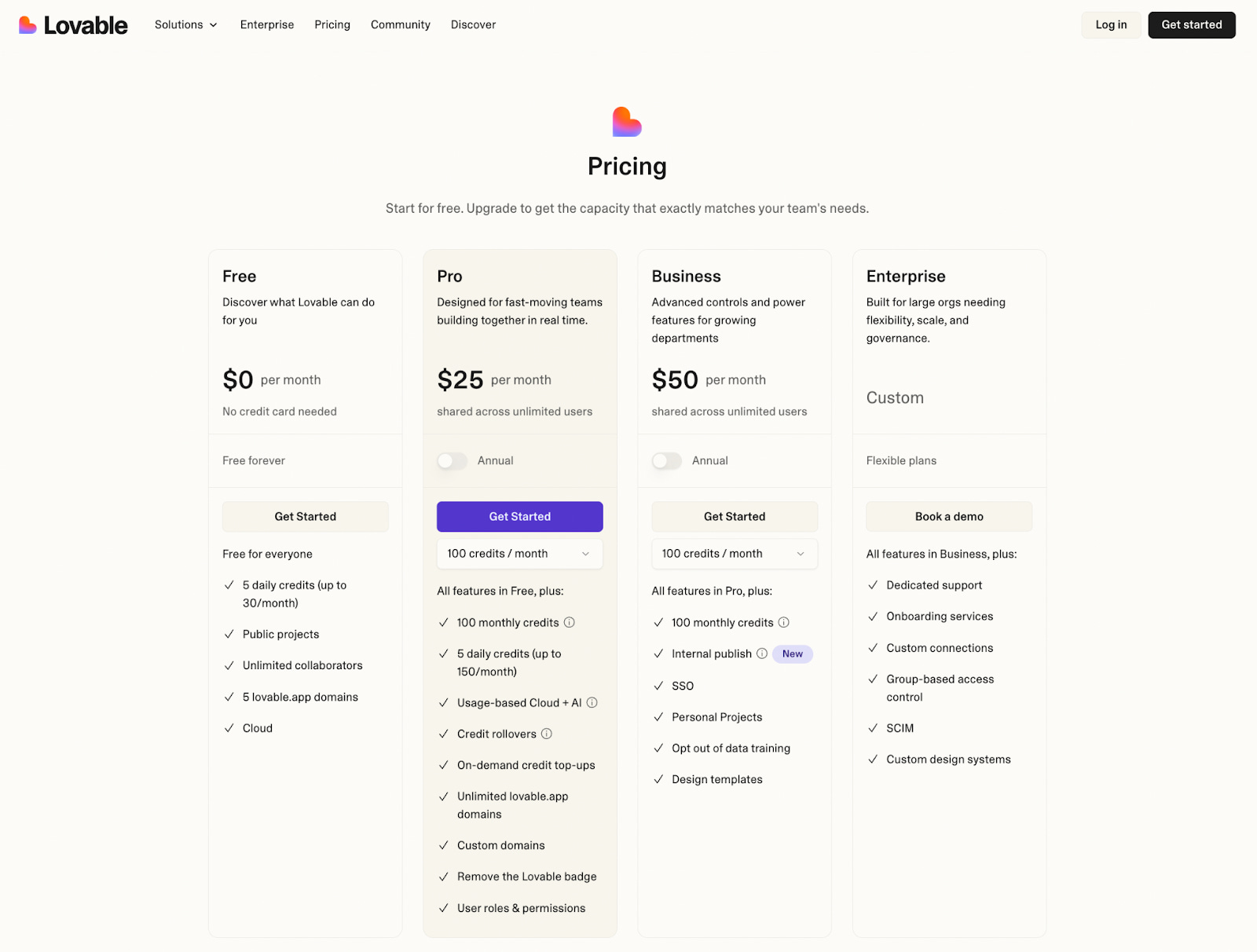
Lovable uses credit-based pricing (see Will user or credit-based pricing prevail in the AI era). It has a good description of its credits on its FAQ (this is a best practice for anyone with a credit-based pricing model).
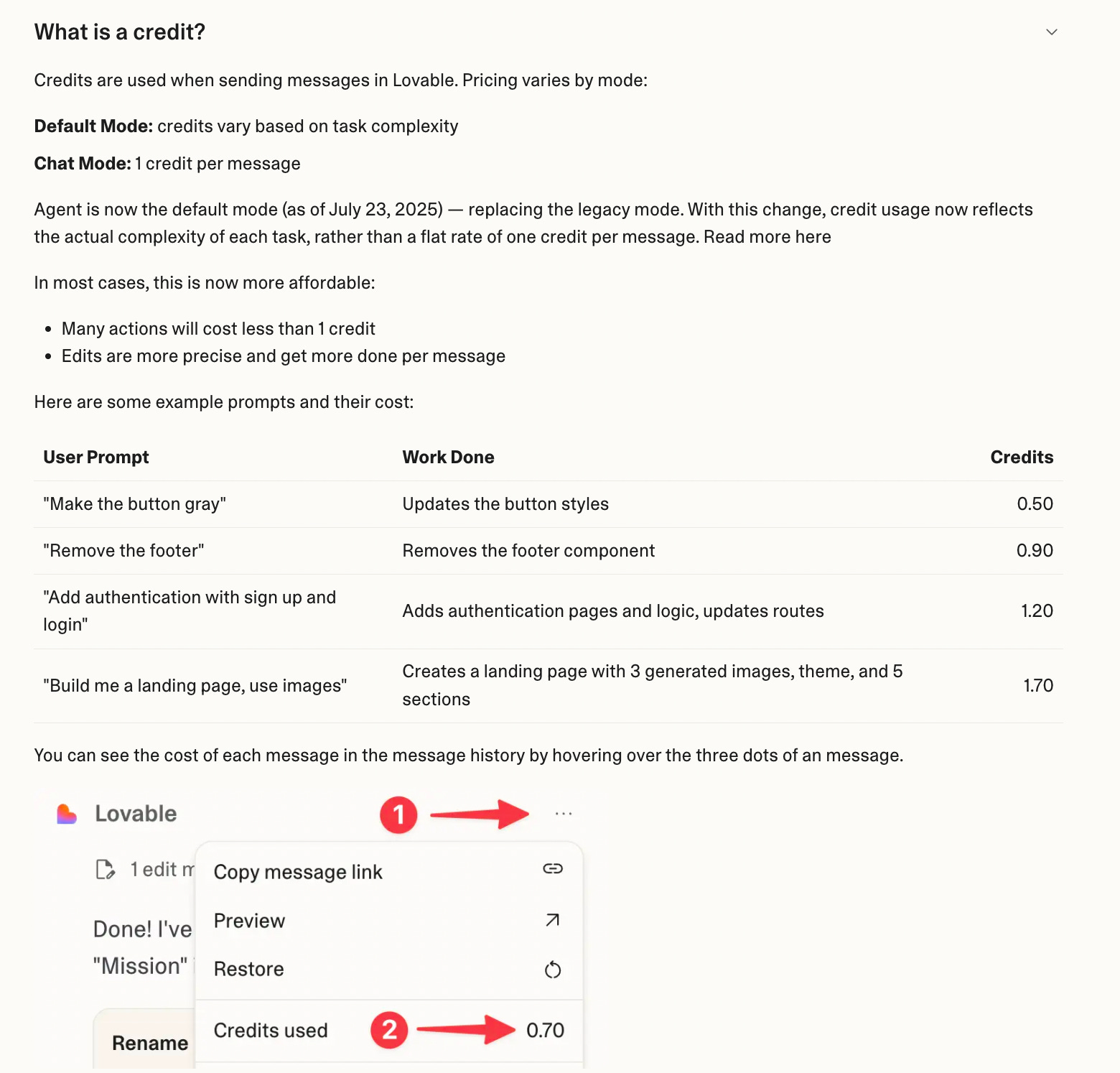
Results of the analysis
So what did the pricing page analysis find?
Here are a few of the key sections from the Advanced report.
Part 1: Snapshot of Current State of Pricing
Lovable now has a modern, public pricing model that is economically sound but harder to understand than key competitors. The urgency is to keep the architecture and make it radically simpler to choose, forecast, and control.
Current model (workspace-first, credits + usage)
Tiers (Observed Data): Free, Pro, Business, Enterprise.
Billing unit (Observed Data): Per workspace per month, with unlimited collaborators; segments primarily use one workspace per team.
Primary metric (Observed Data): Monthly workspace credits consumed by AI-assisted building in the editor.
Runtime monetization (Observed Data): Separate Lovable Cloud and Lovable AI dollar balances per workspace for hosting and runtime AI usage, seeded with free monthly allowances and billed pay-as-you-go when exceeded.
Entry paid anchors (Observed Data, all per workspace per month):
Pro 100 – $25 for 100 monthly credits (plus daily credits).
Business 100 – $50 for 100 monthly credits (plus daily credits, governance features).
Enterprise – custom, no public ranges.
How this maps to segments (Observed Data + Assumption)
Indie makers & solo developers: Free + Pro 100; highly sensitive to simplicity and bill predictability.
Small teams & startup squads: Pro tiers; value shared credits and unlimited collaborators.
SMB / mid-market departments: Business tiers; pay primarily for SSO, roles, data controls, and support.
Enterprise & regulated organizations: Business/Enterprise; runtime usage and governance dominate economics.
Competitive context (Observed Data, normalized to monthly per builder/workspace)
Direct AI app builders cluster at $20–30/month entry for “serious” usage; Lovable’s Pro 100 at $25/month is right in that band.
Base44, Bolt.new, and Softr all use some form of credits/tokens + hosting; Cursor anchors per-seat WTP at $20+/user/month.
Key strengths today (from analysis & COMPASS)
Strong value alignment: credits scale with AI building; Cloud/AI balances scale with app usage.
Unlimited collaborators per workspace feels very fair for teams.
Natural expansion: more apps and more traffic → higher credits and Cloud/AI spend.
Key weaknesses today (from analysis & COMPASS)
Buyers must reason across three constructs (tier, credits, Cloud/AI) and often cannot answer “What will this cost me per month?” without deep reading.
No concrete public guidance on Enterprise price bands (custom only).
No scenario-based examples of “X credits ≈ Y apps / Y workload,” raising bill-shock risk for indie and small teams.
Why this matters now
The AI app-builder category is standardizing around credit/token models, and competitors are pushing simpler, more bundled narratives.
Lovable has moved from opaque pricing to a public model; the next step is to translate structure into a simple story that boosts Free→Paid conversion, protects margins, and unlocks mid-market/enterprise growth.
Pricing SWOT
Most people are familiar with a SWOT analysis (Strengths, Weaknesses, Opportunities, Threats). The Pricing Intelligence agent generates a Pricing SWOT that narrows the focus to pricing issues.
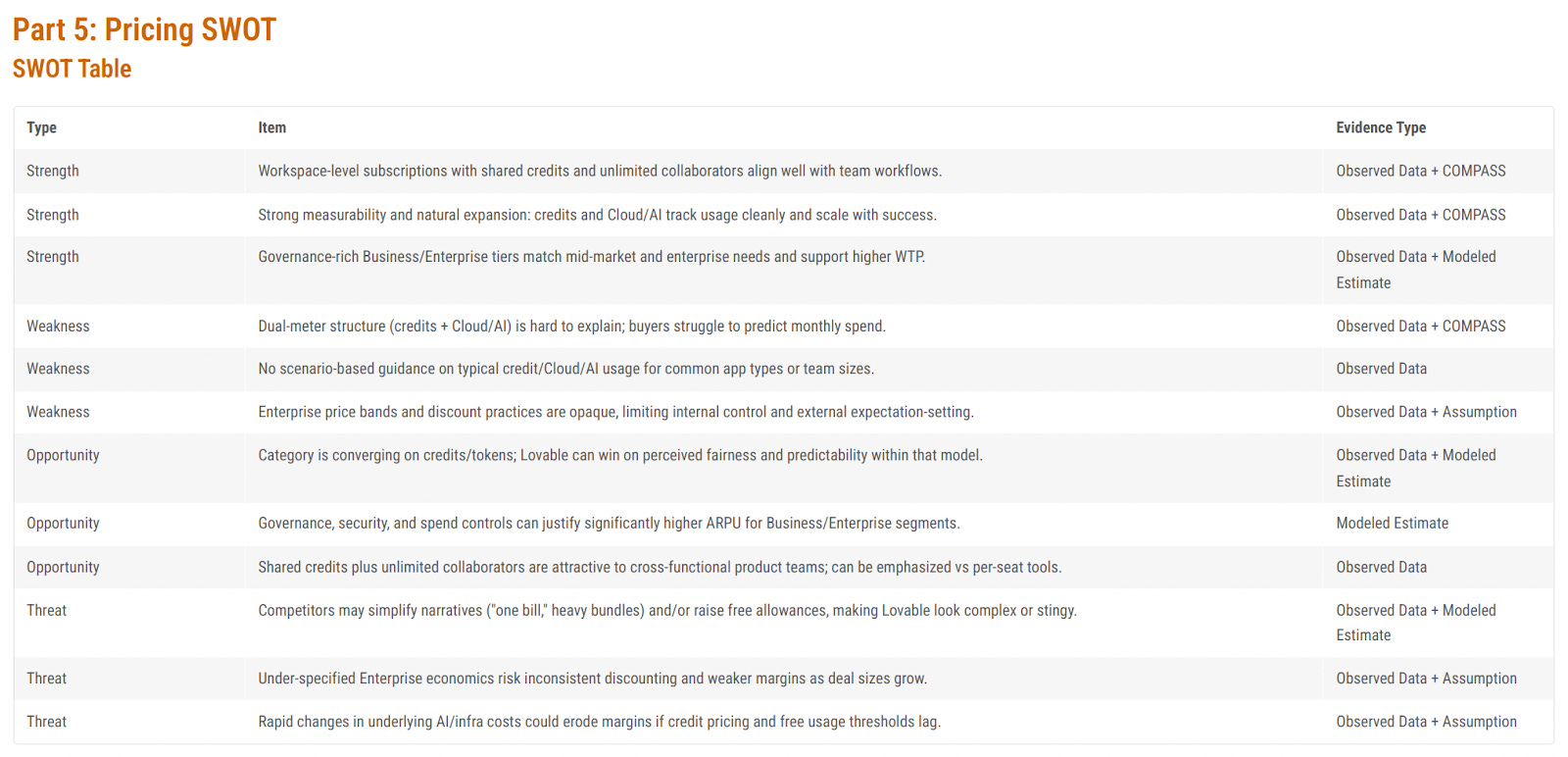
One way to use the SWOT is to combine strengths with opportunities and weaknesses with threats.
Strengths + Opportunities
Leverage workspace‑level subscriptions to win in converging credits/token models
Use shared credits and unlimited collaborators to position “one workspace, one pool of credits” as the simplest way to operate in a market that is standardizing on credits/tokens, emphasizing fairness and predictability versus per‑seat pricing.Use strong measurability to justify higher enterprise ARPU
Combine detailed credit/Cloud/AI usage tracking with governance and spend controls to prove ROI for Business/Enterprise tiers, enabling premium pricing and expansion revenue for teams that need granular visibility and policy enforcement.Exploit governance‑rich enterprise tiers to attract cross‑functional teams
Market advanced governance, security, and shared‑credit collaboration as a safer, more controllable alternative to fragmented per‑seat tools, targeting product, data, and engineering groups that need to collaborate on AI usage at scale.
Weaknesses + Threats
Mitigate dual‑meter complexity before competitors simplify narratives
Address confusion around the credits + Cloud/AI dual meter (e.g., better packaging, clearer quotas, or simplified bundles) to reduce the risk that rivals win with “one bill, simple allowance” stories that make current pricing look complex or stingy.Add scenario‑based usage guidance to protect margins in volatile AI‑infra markets
Create clear scenarios and benchmarks for typical credit/Cloud/AI usage by app type and team size so customers can predict spend, while the company can regularly recalibrate those guides as underlying infra costs and usage patterns change.Increase transparency in enterprise price bands to avoid margin‑eroding discounting
Define and communicate structured discount guardrails and value levers for enterprise deals so that, as deal sizes grow, sellers do not rely on ad‑hoc concessions that create inconsistent economics and weaken long‑term margins.
Mansard COMPASS Analysis
Here is a condensed version of the COMPASS matrix. The full version, available in the report, includes all 14 COMPASS attributes.
COMPASS (Choice of Optimal Metrics for Pricing Agentic Systems & Solutions).
COMPASS is a framework developed by Michael Mansard from Zuora and Steven Forth from valueIQ.ai to help companies navigate AI pricing. One of the Pricing Intelligence sub-agents is built around this framework.
For more on COMPASS, see The ‘COMPASS’ Agentic AI Pricing Metric framework: Your 2-Part Monetization Survival Guide to the Autonomous Age.
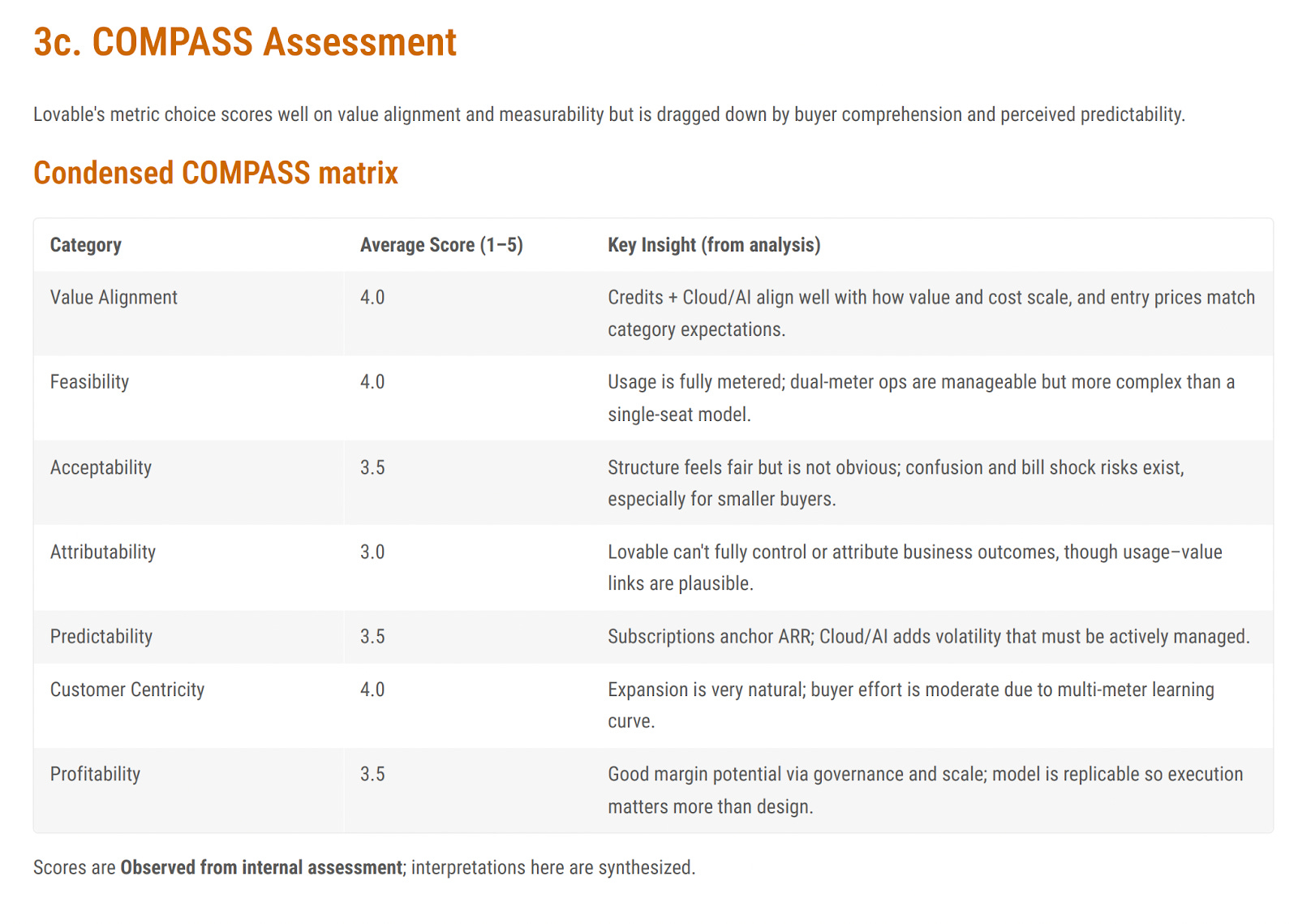
Lovable scores reasonably well (this is even more important when one looks at all 14 factors. The greatest weakness is with Attribution. This is common with most SaaS and AI applications, and it is something we are working on an agent to help solve.
Predictability and Acceptability (to buyer) are also on the weakside. This is a common challenge with credit-based pricing models. We are also planning an agent to help with the design of credit-based pricing models.
Other vibe coding companies to explore
To get more perspective, you may also want to run the pricing pages of other vibe coding apps and compare them.
Go to the valueIQ Pricing Intelligence to get deep insights into the pricing of the different vibe coding apps.
